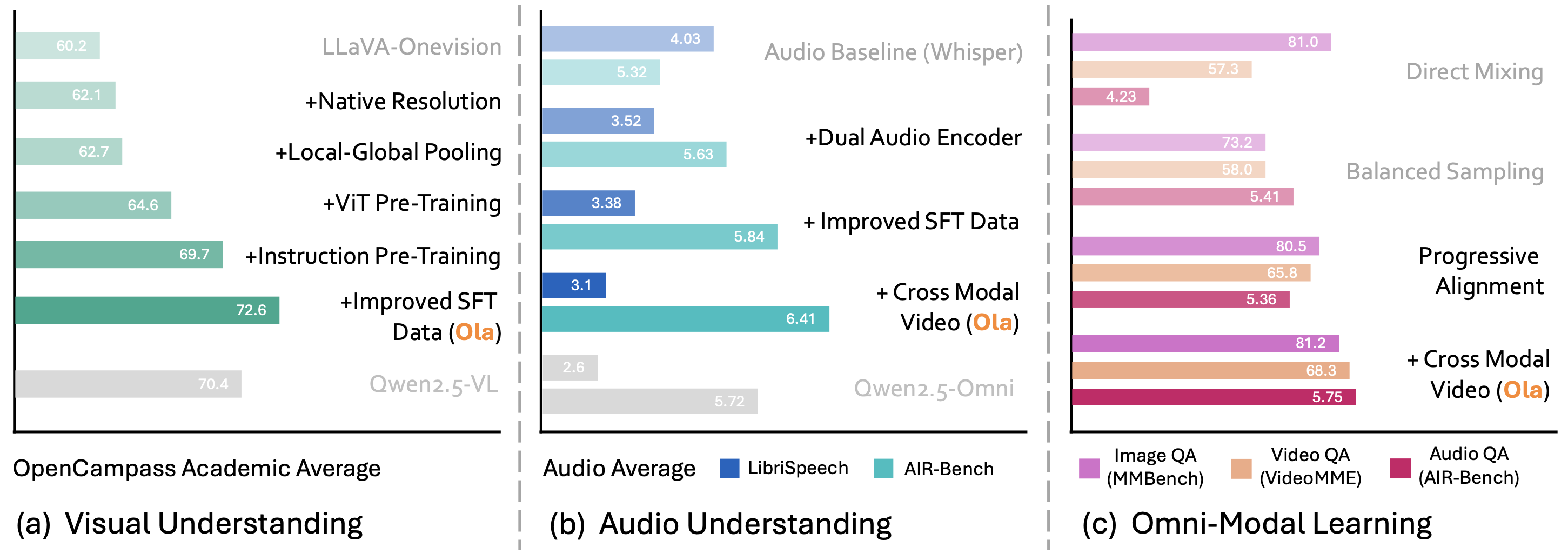
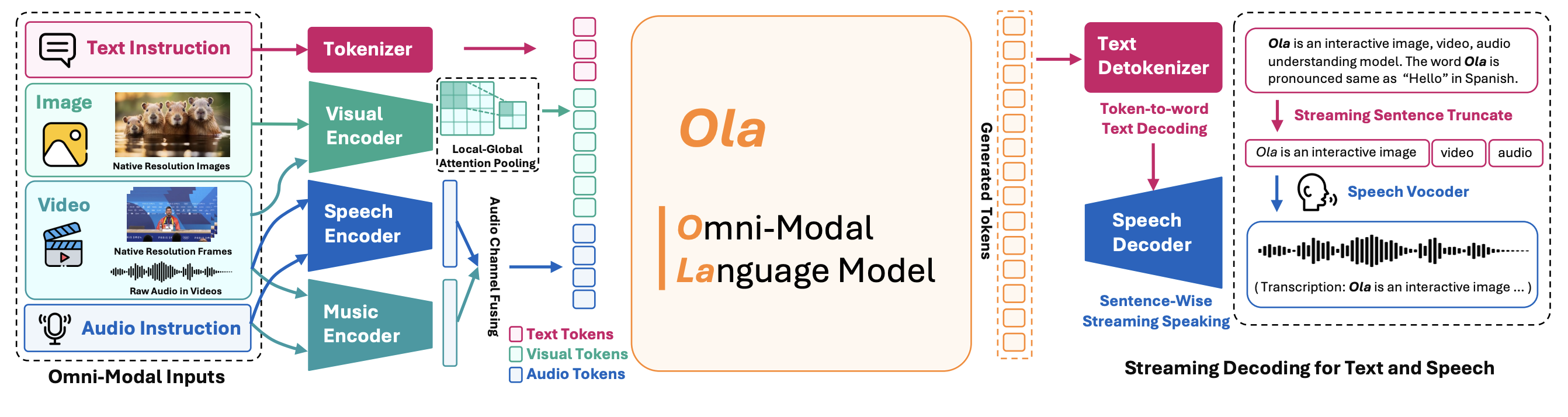
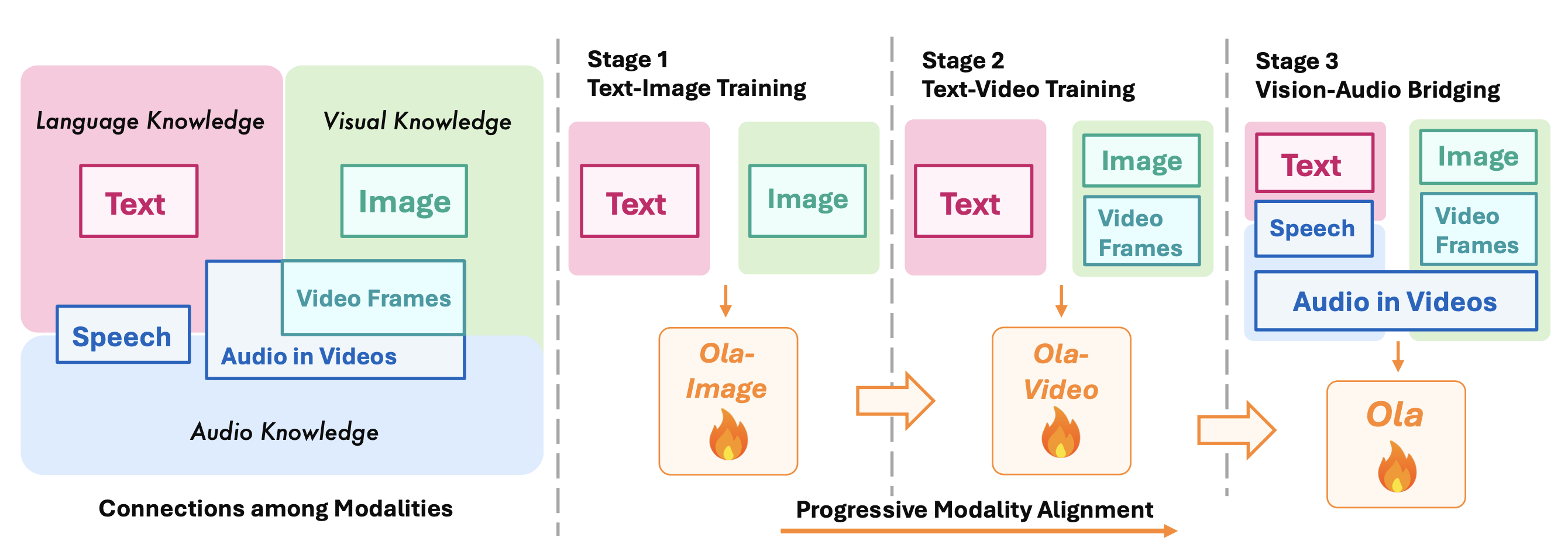
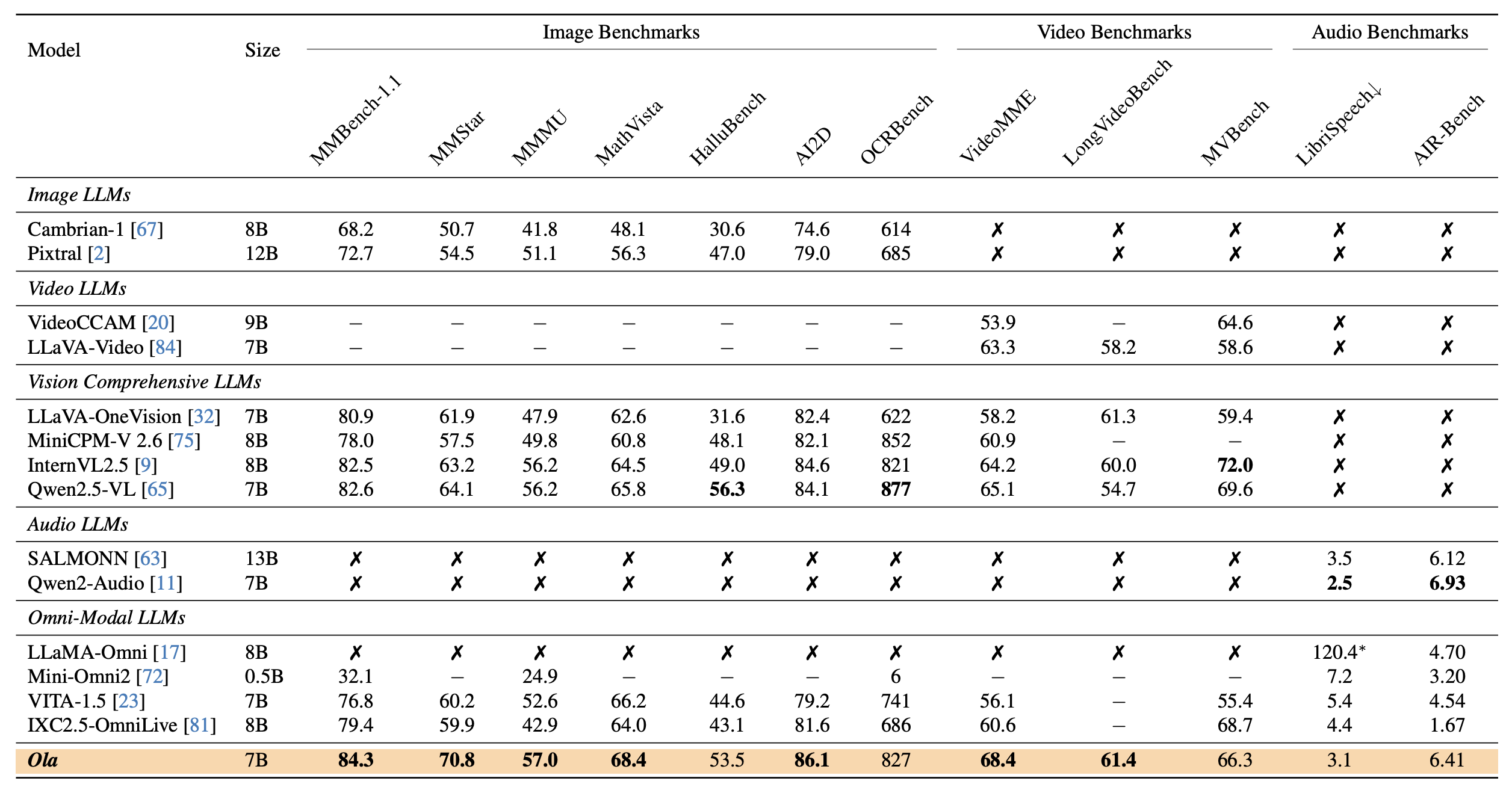
Recent advances in large language models, particularly following GPT-4o, have sparked increasing interest in developing omni-modal models capable of understanding more modalities. While some open-source alternatives have emerged, there is still a notable lag behind specialized single-modality models in performance. In this paper, we present Ola, an Omni-modal language model that achieves competitive performance across image, video, and audio understanding compared to specialized counterparts, pushing the frontiers of the omni-modal language model to a large extent. We conduct a comprehensive exploration of architectural design, data curation, and training strategies essential for building a robust omni-modal model. Ola incorporates advanced visual understanding and audio recognition capabilities through several critical and effective improvements over mainstream baselines. Moreover, we rethink inter-modal relationships during omni-modal training, emphasizing cross-modal alignment with video as a central bridge, and propose a progressive training pipeline that begins with the most distinct modalities and gradually moves towards closer modality alignment. Extensive experiments demonstrate that Ola surpasses existing open omni-modal LLMs across all modalities while achieving highly competitive performance compared to state-of-the-art specialized models of similar sizes. We aim to make Ola a fully open omni-modal understanding solution to advance future research in this emerging field.


@article{liu2025ola,
title={Ola: Pushing the Frontiers of Omni-Modal Language Model with Progressive Modality Alignment},
author={Liu, Zuyan and Dong, Yuhao and Wang, Jiahui and Liu, Ziwei and Hu, Winston and Lu, Jiwen and Rao, Yongming},
journal={arXiv preprint arXiv:2502.04328},
year={2025}
}